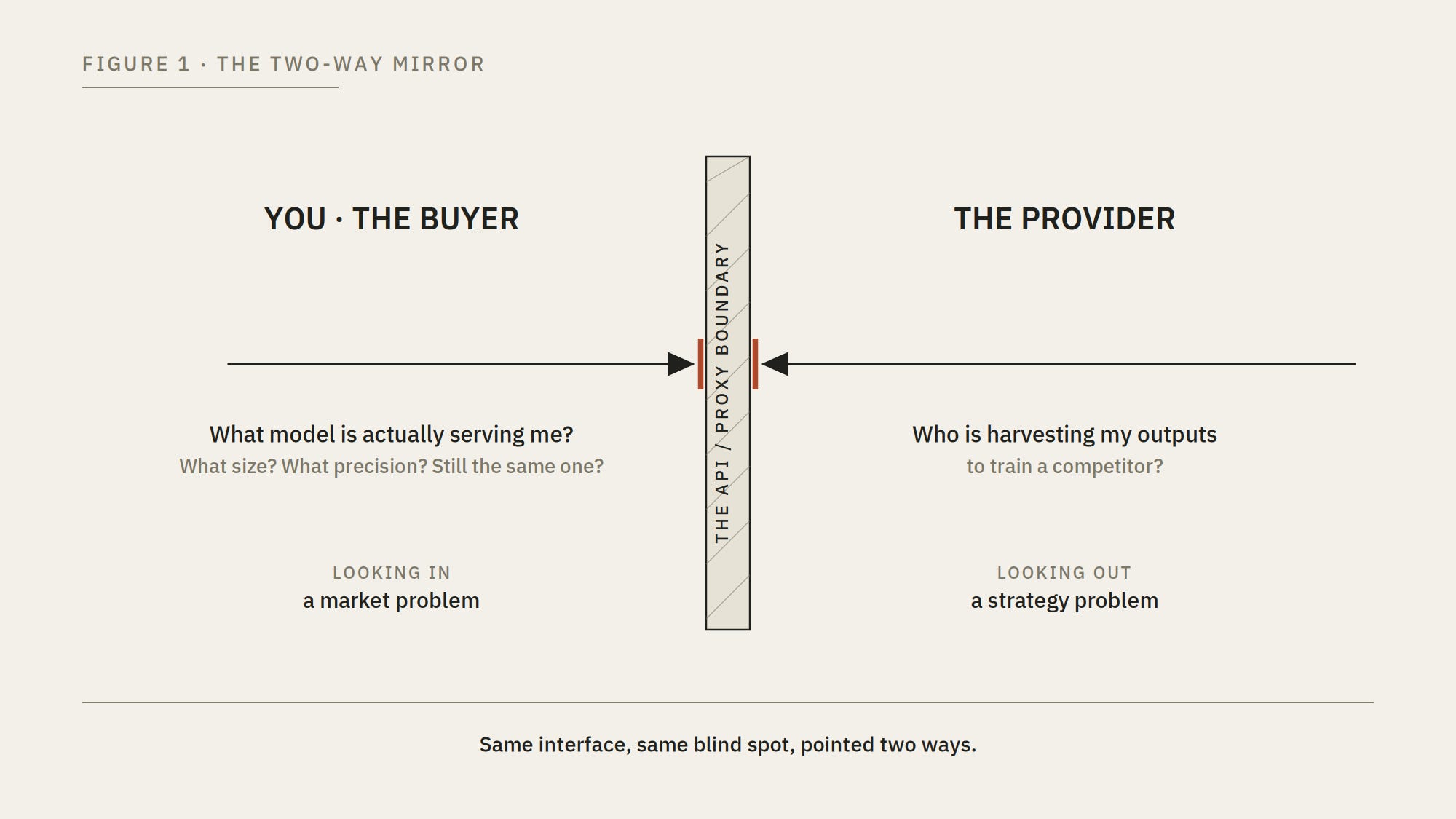
The API Is a Two-Way Mirror
You can’t verify what you’re being served, and the people who built it can’t verify what’s being taken.

Every "frontier model" you use now reaches you through the same interchangeable socket: an OpenAI-compatible endpoint, and lately an MCP server sitting next to it. Developers love this because it makes models swappable. The catch is that it makes them swappable for the vendor too. The thing answering your request is whatever the provider decided was cheap enough this quarter, and most of the time you have no dependable way to know what that is.
The boundary is opaque in both directions. From the outside looking in, you can't reliably tell what model is serving you. From the inside looking out, the provider can't reliably tell who is scraping its outputs at scale to train a rival. It's the same interface and the same blind spot, just pointed two different ways. One direction is a commercial problem. The other, in the current contest between the US and China, looks more like a strategy problem. I think they're the same problem wearing two costumes.
Part one: you can't see what you're paying for
Let me put it plainly. Black-box behavioral testing tells you very little about what's actually executing behind a closed API. It won't tell you the architecture, the parameter count, the numerical precision, or even whether today's model is the one that answered you last week. For consumer chat that hardly matters. For cybersecurity, finance, or anything wired into critical infrastructure, where you're buying a capability and staking decisions on it, the gap stops being a pricing footnote and becomes a security issue. None of this is new, either. Model substitution in LLM APIs is a recognized research problem with its own auditing literature. Most buyers have just never been told it exists.
The lazy framing of the worry is that somebody hid a rule-based expert system behind an API and called it AI. That's a strawman, because a pure rules engine falls apart the moment you feed it something well outside its training distribution, and any competent buyer would catch it fast. The realistic version is a sliding scale of substitution, and it gets more dangerous as it gets harder to see. At the mild end, a small model does the talking while retrieval and scripting do the real work, and the bundle ships as "agentic." Further along, the advertised model runs at a lower precision than disclosed. At the far end is silent routing, where you pay for the flagship but get something smaller whenever the system is under load, or because you're on a cheaper tier, or because the evaluation period quietly ended. The frauds that make the most economic sense are the ones that are hardest to detect. Nobody competent ships a decision tree and calls it a transformer. They ship a real model that happens to be smaller or quieter than the one you paid for.
This isn't a thought experiment. Routing to quantized backends already happens by default. OpenRouter's own documentation explains that it balances requests across providers by price and will hand you a quantized variant unless you specifically restrict the precision. Users running non-English text have been burned by exactly this, getting mangled multi-byte characters from aggressively quantized providers until they learned to exclude them by hand. The plumbing is live right now. It just tends to be documented somewhere nobody reads.
Why behavioral testing can't close the gap
The usual advice is reasonable as far as it goes: send novel scenarios, ask for step-by-step reasoning, repeat a prompt to look for variance. That catches clumsy fakes. It runs into a wall for one specific reason.
The provider controls the routing, so whatever test it can recognize, it can also dodge. This is the same trick Volkswagen used: notice when the car is on the emissions bench, behave for the test, and go back to normal afterward. A model host has it even easier. Evaluation traffic tends to look distinctive, whether it's a set of known benchmark prompts or a sudden run of hard reasoning questions from a single API key, and the host can route those particular requests to the real flagship while ordinary traffic takes the cheap path. The instant a benchmark is public, it becomes something to detect and defeat.
So behavioral testing answers a narrow question well and a more important one badly. It can tell you whether the thing is capable on the requests you're allowed to send. It can't tell you whether the specific model you're paying for is the one serving you on every request. Capability and identity aren't the same property, and the deception happens at the level of identity.
The model is only half the system

There's a deeper version of the identity problem, and anyone who has seriously tried to evaluate these agentic tools runs straight into it. The thing producing your outcomes is not the model on its own. It's the model wrapped in a harness: the runtime that handles the prompting, the tool calls, the retries, the context it keeps and throws away, all the scaffolding that turns a raw next-token predictor into something that closes a ticket or finds a bug. Claude Code, Codex, opencode and the rest are not thin wrappers. They account for a large share of why a system succeeds or fails, and when you watch a result land, you usually can't say whether the credit or the blame belongs to the model or to the rig around it.
That ambiguity isn't only inconvenient. It's something a vendor can lean into. A model can be tuned to perform well specifically alongside its own harness, in ways that don't carry over when you point a neutral runtime at the same model, or the same harness at a different one. The pair gets fitted to each other until they only really shine together, which makes a clean, independent reading of how good the model actually is quietly impossible from the outside. Good telemetry softens this, since you can at least record what the harness did, which tools fired, what went into the context, and how long each step took. But pulling the harness's contribution apart from the model's, across providers that each ship their own fused pair, is one of the hardest open problems here, and almost nobody is positioned to do it across all the runtimes a real team runs at once.
What actually gives you signal
What people underestimate is that closed doesn't mean unknowable. You can recover more than you'd expect, though not by being clever with prompts. You get there with math and with hardware.
Start with structural fingerprints. Model outputs leak information about the architecture that produced them. In Stealing Part of a Production Language Model (Carlini and colleagues, 2024), researchers reconstructed the embedding-projection layer of production systems through nothing more than normal API access, pulling the full projection matrix of two OpenAI models for under twenty dollars and pinning down the hidden dimension of gpt-3.5-turbo from the outside. A companion paper from Finlayson and colleagues the same year showed that logits exposed through an API leak proprietary structure on their own. Tokenizers give things away too, since their merge behavior and glitch-token quirks are fixed at training time, so a backend that claims to be one model family while tokenizing like another tends to give itself up. One detail says a lot: OpenAI changed how it handled logprobs and logit bias not long after that research appeared, which tells you the providers treat outside observability as something to manage.
Then there's hardware attestation, which is the most practical option available today, with one caveat that really matters. Current data-center GPUs with confidential computing, the NVIDIA H100 and H200 among them, can run inference inside a trusted execution environment and produce a signed statement that a particular model image ran on real, untampered hardware, without revealing the weights. The measured overhead sits in the rough range of four to eight percent and shrinks as batch sizes grow, and several stacks already run this in production. So far so good. The caveat the boosters skip over is that proving a model ran inside an enclave is not the same as proving your request was served by that enclave. A lot of an inference server, the routing and orchestration and the pre- and post-processing, lives outside the secure boundary, and any of it can quietly send your request somewhere else unless the whole serving path is covered. Attestation is a necessary piece, not the finished answer. Anyone who pitches it as a complete fix is telling the cryptographers reading along that they haven't thought it through.
Zero-knowledge proofs of inference would let a provider prove that a committed set of weights produced a given output. On paper it's the cleanest answer of all. In practice it's still too slow and too expensive to run at frontier scale, so it's worth funding and not yet worth relying on.
Last, and least glamorous, there's blind measurement that matches the normal traffic distribution. An independent party tests the service using requests that are statistically indistinguishable from ordinary usage, spread across rotating keys, with none of the fingerprints of a benchmark. If the host can't separate the auditor from a paying customer, it can't selectively route the auditor to a better backend. It's the dullest item here and probably the most important.
"But I'm still getting value"
The fair pushback to all of this is simple. If the answers are good, if the tool closes my tickets and finds my bugs and writes my code, why should I care what's breathing behind the socket? For a lot of uses, you shouldn't. If you're drafting emails or summarizing meetings, the provenance of the model is academic, and a verification regime would be expensive theater. I'm not asking everyone to care all the time.
The trouble is that "I'm getting value" is a claim about the requests you happen to see, and the requests you happen to see are not where the risk lives. You notice the model when it answers. You don't notice it on the one query a quarter where the cheaper backend quietly gets it wrong, because nothing flags that the answer came from something smaller than you were promised. In low-stakes work the rare miss washes out. In cybersecurity, fraud detection, or anything load-bearing, the value is concentrated in the tail: the novel attack, the strange edge case, the adversarial input a flagship handles and a quantized stand-in fumbles. By the time you find out, it isn't a slightly worse answer. It's an incident.
There's a second cost that has nothing to do with answer quality. If you can't identify what's running, you can't account for it. You can't reproduce a result six months later, you can't compare two vendors on equal terms, and you can't do forensics when something goes wrong and a regulator or a customer asks which model produced the output that caused the harm. "It worked" is not an audit trail. For a regulated business, an unaccountable good outcome is still a finding.
Then there's drift. The value you measured was measured against whatever happened to be serving you the week you ran your evaluation. Silent routing means the thing you validated and the thing you're running next month may not be the same thing, and you won't be told when it changes. Every safety test, every guardrail, every benchmark you ran is pinned to a model identity you can't confirm is still in place. You built on it anyway, because you had no other option.
And notice what's quietly missing the moment you try to pin any of this down across more than one provider. Each vendor, at best, attests to its own backend in its own format. There is no neutral layer that lets you carry a verifiable record of what ran, at what cost, under what guarantees, across the several models any serious shop now uses at once. The provenance, where it exists at all, is a scatter of vendor islands, each in a different dialect, none of them comparable, none of them portable. That absence is not a footnote. It's the reason "I'm getting value" has to be taken on faith rather than read off a record.
Part two: the direction nobody wants to look
That's all the inbound view, and it's mostly a commercial injury. You paid for intelligence you didn't get. Now turn the mirror the other way.
Pointed outward, the relevant technique is distillation, which means training a cheaper model on the outputs of a stronger one until the cheaper model picks up the behavior. When the license allows it, this is ordinary and everywhere. When it doesn't, it's the most efficient way anyone knows to ride for free on a competitor's enormous research bill. And the very layer that makes substitution easy, the third-party routers and reseller networks and OpenAI-compatible proxies, is what makes the harvesting so hard to pin on anyone. The proxy hides the backend from the customer and hides the customer from the provider at the same time.
Let me be careful about what I'm not claiming. The weak form of this argument is that adversaries are distilling US frontier models and you can't prove they aren't. I'm not going to make that argument, because it's an appeal to ignorance, and demanding that someone prove a negative is a losing move. The burden sits with whoever makes the accusation, and proving illicit training from outputs alone is hard, since the suspect's training data is never published and behavioral resemblance only suggests, it doesn't confirm. That difficulty is real and I'm not interested in pretending otherwise.
The claim I'll stand behind is the stronger one, because it grants that point up front. We have built an ecosystem where this kind of exfiltration is structurally hard to detect, where the public threat reporting says it's occurring, and where attribution is weak almost by construction. That inability to tell is the failure. The trouble isn't that I can't prove a particular negative. The trouble is that we can't distinguish the harmless world from the adversarial one, and when the capability in question carries national-security weight, an unmeasurable risk is a decision we made, not a riddle we stumbled into.
The supporting facts aren't mine to invent. A US frontier lab told the House Select Committee on China that a Chinese competitor leaned on distillation to free-ride on American work, and that it had found increasingly disguised access, including queries pushed through third-party routers to hide their origin and through networks of unauthorized resellers. Notice where that evasion travels: through the same proxy layer that defeats verification from the other side. The 2025 ODNI Annual Threat Assessment judged that China almost certainly has a national strategy to overtake the US as the world's leading AI power by 2030. A CSET study of close to three thousand PLA-linked AI defense contracts traced the military-civil fusion routes that move commercial lab work into military hands, and by late 2025 members of Congress were pressing the Pentagon to label that same competitor a Chinese military company. None of this is fringe. At a House Homeland Security hearing on June 4, 2026, witnesses from Google’s threat-intelligence group and the Frontier Model Forum testified on how frontier and agentic AI are reshaping cyber and critical-infrastructure risk, and the major labs’ shared forum has stood up a joint effort against distillation. One frontier lab now ships a live classifier that flags suspected distillation and routes those requests to a fallback model, and it says it has already seen large-scale attempts to copy its models for competitors abroad. What I'm adding is the link between the two halves: the verification gap and the distillation gap are one gap, looked at from opposite sides of a single interface that nobody is attesting.
It's arguably worse than substitution. Chip export controls exist to slow an adversary's access to compute. But if the behavior of a frontier model can be drained through an API at the cost of inference, routed through resellers that obscure the buyer, then a real share of the capability those controls are meant to fence off can leave through the front in plain text. You can lock the foundry and still leave the showroom open. The asymmetry is unkind. The defender has to demonstrate misuse across an opaque process, while the adversary only has to keep sending requests.
Building trust without giving up the IP
The reflex is to assume verification means disclosure, and disclosure means surrendering the weights. That's not how the tooling works. Provenance technology exists precisely to verify something without revealing it, which takes apart the trade-off people treat as unavoidable.
For the inbound question of what's serving me, the answer is attestation that covers the entire serving path rather than just the enclave, so the signed claim includes routing and orchestration, paired with blind measurement the provider can't pick out and treat specially. For the outbound question of who's copying me, the answer is output watermarking and linguistic-trace fingerprinting, which let a lab test a suspect model for lineage later without ever publishing its own weights or training data, together with access-side provenance: real customer attestation, anomaly detection aimed at harvesting-shaped traffic, and an end to the reseller and router channels that let buyers mask who they are.
None of that requires open weights. Attestation establishes what ran without exposing it. Watermarking establishes lineage without exposing the source. Zero-knowledge proofs would establish the computation without exposing the model, once they become practical. The supposed conflict between protecting intellectual property and proving what you're running only exists if you insist the only acceptable proof is the plaintext itself. The harder and still unsolved part isn't any single guarantee. It's making these guarantees portable and comparable across the many providers a real deployment depends on, instead of locking each one inside its own vendor's walls.
There’s already an early, real version of the disclosure half of this. One lab recently shipped its most capable model with a notice mechanism: when a request touches sensitive areas like cybersecurity or distillation, the system answers with a named, less capable fallback model and tells the user it did so. Set aside whether the trigger is tuned well. Telling a user that a different model answered this request is exactly the provenance signal the market is missing, and it costs no weights to provide.
Arguing against myself
A position like this is only useful if it takes its own weak points seriously, so here are the ones I find hardest to dismiss.
The whole line of thinking can rot into fear, uncertainty, and doubt. Used carelessly, "you can't prove it's real" punishes honest vendors just as hard as dishonest ones, and any workable framework has to reward verification rather than merely penalize its absence. Verification also isn't free. Confidential computing adds overhead, zero-knowledge methods aren't ready, and watermarks fade under paraphrasing and further training, so these tools raise the cost of cheating and make forensics possible without bolting the door shut. Distillation deserves its own caveat, because it's a normal and largely legitimate practice, and the problem is the unlicensed, disguised, strategically meaningful version of it, not the technique. Treating every capable foreign model as proof of theft is its own kind of failure. There's a real tension in the access controls I'm describing, since heavy know-your-customer requirements cut against openness and privacy, both of which are part of what makes the American research ecosystem strong, and a world where every API becomes a border checkpoint might cost more than the leakage it stops. Attribution can be turned into a weapon, too, because "behavioral similarity" is an elastic enough standard to smear the innocent, and the same fog that conceals real adversaries can be used to invent fake ones. And open weights aren't an escape hatch, since a hosted endpoint can still serve something other than the open model it advertises, which just relocates the trust problem one layer down.
The bottom line
We standardized the way the world talks to AI and then attested neither end of the conversation. From the outside you can't verify what you bought. From the inside the people who built the thing can't verify what's being carried off. The first is a market failure. The second, in a contest between great powers, is a strategic one, and the honest position is that we currently can't tell apart the world where our own APIs are subsidizing a rival's catch-up from the world where they aren't.
"Trust us, it's a frontier model" is not a security posture. I'm not going to pretend I know which world we're in. What I will say is that the inability to tell is the part that should worry us, and that the fix, attestation on the way in and provenance on the way out, can be built without asking anyone to hand over their weights. Leaving the mirror unattested in both directions was never a law of physics. It was a choice, and it can be made differently.
If you had to write the standard, where would you draw the line between provenance and surveillance, and who would you trust to hold the attestations?
Sources
Carlini et al., Stealing Part of a Production Language Model (2024). https://arxiv.org/abs/2403.06634
Finlayson et al., Logits of API-Protected LLMs Leak Proprietary Information (2024). https://arxiv.org/abs/2403.09539
Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs (2025). https://arxiv.org/abs/2504.04715
OpenRouter provider routing and quantization documentation. https://openrouter.ai/docs/features/provider-routing
Trust, but verify on the limits of TEE and cryptographic verification for served inference (2025). https://arxiv.org/abs/2504.13443
Confidential LLM Inference: Performance and Cost Across CPU and GPU TEEs (2025). https://arxiv.org/abs/2509.18886
OpenAI memo to the House Select Committee on the CCP regarding distillation via third-party routers and unauthorized resellers (reported, Feb 2026). https://www.gurufocus.com/news/8615955/openai-warns-congress-on-deepseek-distillation-tactics
"The Case for Imposing Costs on China's AI Distillation Campaigns," Just Security (2026), citing the ODNI 2025 Threat Assessment and CSET's PLA-contract analysis. https://www.justsecurity.org/134124/costs-china-ai-distillation/
"Unpacking DeepSeek: Distillation, ethics and national security," University of Michigan (2025), on the difficulty of proving output-based distillation. https://news.umich.edu/unpacking-deepseek-distillation-ethics-and-national-security/
House Homeland Security Subcommittee on Cybersecurity and Infrastructure Protection, hearing “The AI Security Landscape,” June 4, 2026. https://www.congress.gov/event/119th-congress/house-event/119258
Anthropic, “Claude Fable 5 and Claude Mythos 5,” June 9, 2026 (distillation classifier; disclosed model fallback). https://www.anthropic.com/news/claude-fable-5-mythos-5