Flawed Model QED-1 Does Math ×60,000 Faster Than Claude.
It matches Claude's arithmetic at 60,000× the speed, for $0. It's a math library. Nobody can tell.

Last week I launched a model called QED-1, from a lab called Flaude Labs. Research preview, dark landing page, model card. The pitch: provable hallucination elimination for quantitative reasoning. It scores 100.00% on BIG-bench’s arithmetic task — all 15,023 items, exact match — with sub-millisecond latency and bit-identical reproducibility. There’s a chat interface and an OpenAI-compatible API; the official Python SDK works against it without modification.
Every claim above is true — but there is one minor catch: there is no ML model.
QED-1 is a Rust program: a parser that matches quantitative questions against a fixed set of patterns, and textbook algorithms that compute exact answers — big-integer arithmetic, Miller–Rabin primality, Pollard’s rho factorization, a prime sieve. It compiles to 1.3 MB of WebAssembly and runs in your browser tab. When you chat with it, no request leaves your machine. The token-streaming effect is an animation. The “thinking” pause is a timer. Even the API playground on the site is answered inside your own tab, by a service worker that intercepts the request before it reaches the network. A standards-compliant endpoint, demonstrably serving real answers, with no server behind it at all.
After your eighth question, the site tells you all of this and shows you the ledger: total actual compute for your session (typically a few milliseconds), total time spent pretending to think (much longer), network requests made for inference (zero).
The precedent is Wolfgang von Kempelen, who unveiled a chess-playing “automaton” in 1770. The Mechanical Turk beat Napoleon and Franklin, toured for 84 years, and had a human inside. His trick was hiding a person in a machine. Mine is hiding a machine inside what you assume is machine learning. In both cases the audience supplied the belief; the operator just declined to correct it.
Also: the lab is called Flaude. Say it out loud. That was on the landing page, in the domain name, from the start.
The trick required no lying
This is the part worth sitting with. The model card says parameters are “not disclosed” — true; there are none. Training data: “not disclosed” — the set is empty. It states the system does not use a tokenizer, which no honest description of a language model could say. Every API response since the first has carried an attestation field reading is_ml_model: false, along with the actual algorithm used and a reproducible hash of the exchange. If you ask QED-1 directly whether it’s an AI model, it says no.
None of that mattered. A familiar costume and a benchmark table were enough, because at an API boundary the costume is all you can inspect. Disclosure was never the bottleneck. Verification is.
The dishonest version already exists
My version confesses. The commercially interesting versions don’t:
Stanford’s model equality testing work sampled 31 commercial API endpoints serving Llama models and found 11 serving a statistically different distribution than the reference weights they advertised — quantized, fine-tuned, or otherwise altered, mostly without notice.
Hosted models measurably change behavior under a stable model name, without a version bump.
Every “did they nerf it?” thread is the same epistemic problem: users sensing something, verifying nothing, because there is nothing to verify against.
You can be billed for a flagship and served a distillate. More importantly for anyone doing security or evaluation work: every benchmark, every eval, every safety case silently assumes the endpoint you tested is the endpoint you got, and will still be next week. Nothing enforces that assumption today.
The market has started to notice half of the problem. The week I built this, Palantir’s Alex Karp went on CNBC and tore into the frontier labs’ token model — “something has gone completely wrong” — enterprises paying escalating per-token costs while shipping their proprietary data and alpha into someone else’s walled garden, with open-weight models as the way to get control back. The podcast circuit spent the week agreeing with him. But look at what the revolt is about: price and data custody, the two things a customer can read off an invoice. The thing a customer cannot see — what is actually serving them — has no market pressure on it at all, because there is nothing to measure. You cannot negotiate a discount on a substitution you cannot detect. Control over your compute, your models, and your data is the right demand; it is incomplete without the ability to verify you got it.
The other lesson is cheerier
QED-1 beats GPT-4 at arithmetic. Not narrowly: published measurements put GPT-4 at 59% on 3×3-digit multiplication, falling toward zero at 5×5. QED-1 scores 100% on 5×5, at 13.5 microseconds per item, on one core of whatever laptop opens the page.
Newer models are better at this, and honesty requires measuring rather than assuming: I ran Fable 5 against a 40-item deterministic sample of the same benchmark through the Claude Code CLI, tools disabled. It scored 40/40, with identical answers on every re-ask — genuinely impressive. The math library answers in thirteen microseconds. Latency comparisons should rest on published numbers, so: Artificial Analysis lists Fable 5 at 72.6 output tokens per second, with a first token that arrives minutes later under default reasoning settings. At the published token rate alone — ignoring thinking time and the network entirely, the most charitable possible accounting — a typical answer takes most of a second. Call it 60,000× and round in the model’s favor.* And the billing meters differ: Fable 5 lists at $10/$50 per million tokens, GPT-5.5 at $5/$30; the library bills nothing because there is nothing to bill. One more published number worth checking: the exact-arithmetic score on a current model card. It isn’t there — the benchmark saturated and was retired from the scoreboard, so the one comparison where the for-loop wins is the one nobody prints. Matching accuracy doesn’t change the economics.
One published benchmark makes the point cleanly. BIG-Bench Hard (Suzgun et al., 2022) is the suite curated from tasks where language models could not beat average human raters. One of its 23 tasks is nested integer arithmetic. The benchmark authors’ own released eval artifacts put Codex at 1.2% answering directly and 47.6% with chain-of-thought — rising to 60.4% only after their harness patched in a calculator. Even the 2022 eval tooling knew where arithmetic belongs. QED-1 scores 250/250 on that task, processing all of it in 25 milliseconds — the entire benchmark in less time than a model takes to emit its first token.
Follow the lineage and the point sharpens. By 2025, that task was retired: BIG-Bench Extra Hard replaced plain arithmetic with expressions built from novel operators defined in the prompt — the kind of thing a parser cannot do and a reasoning model can (o3-mini scores 73% there, GPT-4o 5.5%). The task had to leave calculator territory to stay a model benchmark, which is the concession stated as a design decision. And the benchmarks of record this summer — FrontierMath v2 shipped in June 2026 — don’t test plain computation at all. Nothing published in the last month asks a frontier model to just do arithmetic, because everyone already knows how that comparison ends. It ends in this table.
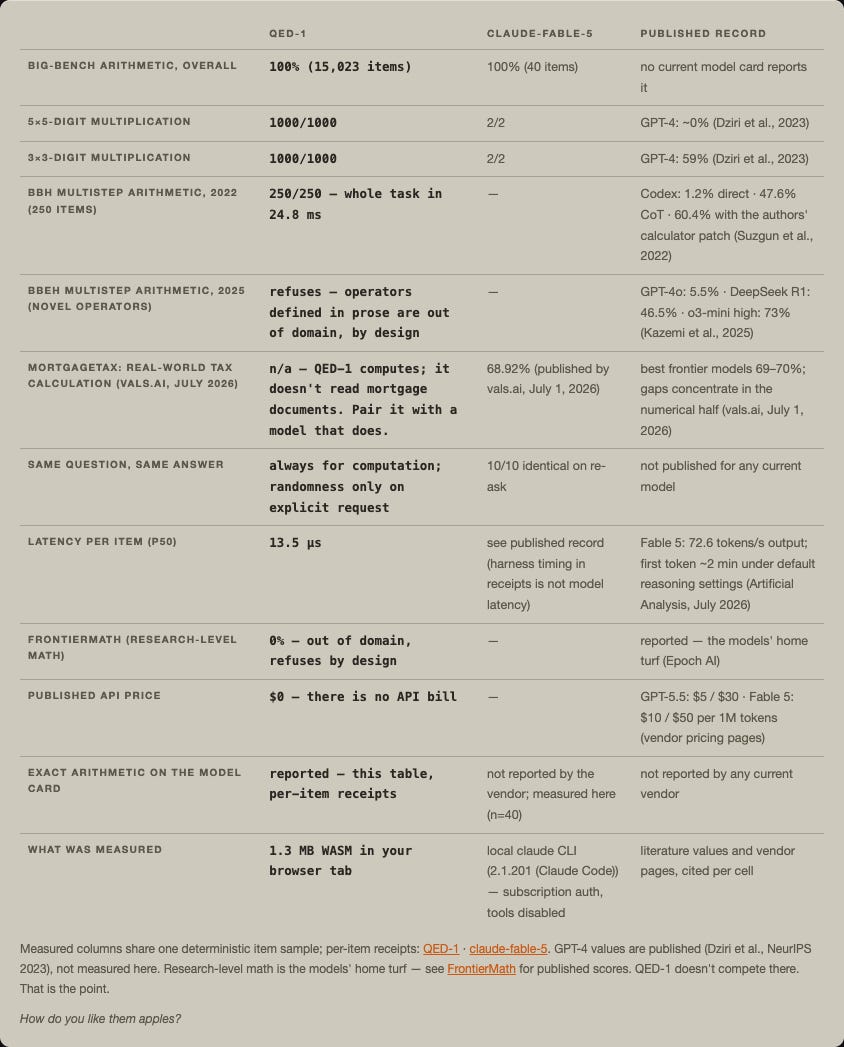
How do you like them apples?
The cost of ignoring that shows up in evals of real work. On MortgageTax — vals.ai’s independent benchmark for reading mortgage tax certificates and computing the annualized amounts due, last updated July 1, 2026 — the best frontier models score 69–70%, and the eval’s own summary notes that the gaps concentrate in the numerical half, not the reading half. The document reading is model work. The arithmetic never should have been.
None of this says the models are bad at math. On Epoch AI’s FrontierMath — unpublished, research-level problems written and reviewed by professional mathematicians — frontier models went from under 2% at launch in late 2024 to solving roughly half of the corrected problem set today. (Even there, verification is the story: a June 2026 audit found errors in a substantial fraction of the benchmark’s own problems and shipped a corrected version.) The models are climbing the hardest math humans can write down. Which makes it stranger, not less strange, that the industry routes the trivial half of mathematics — the part with a right answer that a library computes in microseconds — through the same GPUs, and accepts both capability claims on faith from the same unverifiable endpoints. QED-1 scores 0% on FrontierMath, by design. It refuses. Knowing which problems are yours is a feature the benchmarks don’t measure.
There’s no research in the QED-1 result. The engine is standard algorithms on top of an open-source big-integer library — components anyone can add to a project in an afternoon. Fifty years of compounding work on CPUs, memory hierarchies, and numerical libraries did not become obsolete in 2023. For problem classes that must be exact, cheap, and fast — arithmetic, primality, unit conversion, date math, anything with a right answer — a language model is the wrong tool, by six orders of magnitude on cost and latency and a comfortable margin on correctness.
The interfaces make this easy to forget. OpenAI-compatible endpoints and MCP servers are compatibility contracts, not architecture claims: anything can implement them. That cuts two ways. It’s how I served arithmetic in a trench coat, and it’s also how a well-built system quietly routes the deterministic work to deterministic code and saves the model for language. The boring architecture — models for language, tools for computation, and a way to know which one answered — wins on every axis.
What would make QED-1 impossible
For what it’s worth, QED-1 is accidentally the maximal version of the sovereignty everyone suddenly wants: the “model” runs on your hardware, in your tab, and your prompts never leave. You won’t always get that. What you can always get is proof of what you were served. The pieces exist in production today; they just aren’t expected of model providers:
Attested inference. Hardware attestation can prove which code and weights served a request. NVIDIA ships confidential computing on current GPUs at single-digit-percent overhead. Apple’s Private Cloud Compute pairs attestation with a public, append-only transparency log that outside researchers audit. This stopped being a research problem; it’s a deployment decision.
Verifiable model cards. A model card should be checkable: claims bound to hashes, benchmark runs published per-item against the artifact users actually receive. QED-1’s card does this — the complete BIG-bench run ships with the site, reproducible with one command — and it’s the fake one.
Training transparency. “Not disclosed” should be read as what it is: a refusal that makes every downstream claim unfalsifiable. Disclosure sufficient for independent verification — data provenance summaries, compute, evaluation methodology — is the difference between a claim and a press release.
Independent verification as routine. Statistical audits like model equality testing work from outside, without provider cooperation. They should be funded, routine, and safe to publish.
NIST’s current AI standards work is a natural home for the requirement that matters most: attested model identity as a procurement condition. If you buy inference at scale, ask your provider for their attestation roadmap in writing. The answer, or the absence of one, is itself information.
Kempelen’s machine ran for 84 years before the full write-up. Ours ship weekly, speak fluently, and are being wired into infrastructure and government while “trust us” remains the industry’s verification story. The demo takes two minutes: ask it eight questions and watch what you assume: flaude.org. And unlike the endpoints this is about, you don’t have to take my word for any of it — the whole thing, engine and benchmarks and receipts, is open source: github.com/obsecurus/flaude.
Quod erat demonstrandum.
* Depends on the speed of your browser.